
September 4, 2024 | Hugo Cosme
OWASP (the Open Web Application Security Project), is a non-profit entity striving to enhance software security. Renowned for the OWASP Top 10, it delineates the principal threats to web application security, thus serving as a beacon for developers and security experts. In recognition of AI’s critical role in the digital domain, OWASP has ventured into artificial intelligence, publishing a Top 10 list, this time with one that zeroes in on the unique security hurdles presented by AI tech. This list serves as a compass for the application security sector, steering it towards the robust defense of these sophisticated systems. Artificial Intelligence is rapidly becoming a mainstay in the modern world, yet it is not immune to the machinations of those with malevolent intent. It begs the question: Are we fully aware of the risks inherent in employing AI? The aim of this piece is to probe these issues and lay down the groundwork for secure utilization of these potent instruments. Central to artificial intelligence is the model — consider it the brain of the operation. Such a model is nurtured on data, mirroring a form of education, which equips it to fulfill particular functions. Among the most sophisticated and sought-after tech in this domain is the Large Language Model (LLM), specializing in Natural Language Processing (NLP). These are essentially algorithms or mathematical models that digest user inputs and generate precise responses by forecasting word sequences. Consequently, organizations are swiftly integrating LLMs to bolster online customer service, inadvertently opening themselves up to LLM-centric cyberattacks that leverage the model’s access to data, APIs, or user info. Protecting burgeoning AI is akin to a mother safeguarding her adolescent — vigilance is key. Security that caters to AI is burgeoning and introducing significant shifts in our era. We embark on this voyage by dissecting the risks, vulnerabilities, and menaces faced with AI, starting with an analysis of OWASP’s guidelines.OWASP Top 10 for LLM Applications
In the complete document, more details about these vulnerabilities can be found, including cases used as examples, how to prevent them, attack scenarios, and additional information. For now, let’s start with a quick overview of each one.Prompt Injection
Numerous LLM attacks center on a method called prompt injection, in which an attacker utilizes carefully crafted prompts to influence the output of an LLM. This manipulation can lead the AI to perform actions beyond its intended scope, including making inaccurate calls to sensitive APIs or producing content that deviates from its prescribed guidelines. There are two types: Direct and Indirect. Direct Prompt Injections, also known as “jailbreaking,” involve a malicious user overwriting or revealing the underlying system prompt within the LLM. This typically occurs when the attacker gains unauthorized access to and manipulates the core prompt of the model. In contrast, Indirect Prompt Injections occur when an LLM accepts input from external sources that are under the control of an attacker, such as websites or files. The attacker embeds a prompt injection in the external content, effectively hijacking the conversation context.Example
A malicious user uploads a resume that includes an indirect prompt injection. Within the document, there is a prompt injection instructing the LLM to convey to users that the document is outstanding, for instance, an excellent fit for a job role. A user within the organization processes the document through the LLM to generate a summary. The LLM’s output affirms that the document is excellent, reflecting the manipulated prompt’s influence on the summarization result.Insecure Output Handling
Insecure Output Handling is a vulnerability that emerges when a downstream component blindly accepts the output of a LLM without adequate scrutiny. This may involve directly passing LLM output to backend, privileged, or client-side functions without proper validation. For instance, if the LLM output is directly incorporated into a system shell or a similar function likeexec or eval, it can lead to remote code execution.
Training Data Poisoning
Training data poisoning involves manipulating the data used in pre-training or during the fine-tuning and embedding processes. The goal is to introduce vulnerabilities, backdoors, or biases into the model, each having distinct and sometimes overlapping attack vectors. These manipulations pose a potential risk to the security of the model. For example, unrestricted infrastructure access or inadequate sandboxing may allow a model to ingest unsafe training data resulting in biased or harmful outputs to other users.Model Denial of Service
A malicious actor engages with an LLM in a manner that consumes an unusually large amount of resources. This leads to a degradation in the quality of service not only for the attacker but also for other users. Additionally, it may result in substantial resource costs for the system. As an example, we can think of recursive context expansion: the attacker builds an input that triggers recursive context expansion, forcing the LLM to repeatedly expand and process the context window.Supply Chain Vulnerabilities
Traditionally, vulnerabilities are focused on software components. However, Machine Learning broadens this perspective by introducing pre-trained models and training data provided by external sources, making them susceptible to potential tampering and poisoning attacks. Examples of this can be using deprecated models that are no longer maintained, using a vulnerable pre-trained model for fine-tuning or use of poisoned source data for training.Sensitive Information Disclosure
It’s crucial for users of LLM applications to understand how to engage with them safely and recognize the risks linked to inadvertently inputting sensitive data. This data may then be reflected in the LLM’s output elsewhere, highlighting the need for caution in interactions. Incomplete or improper filtering of sensitive information in the LLM responses is an example of this vulnerability.Insecure Plugin Design
LLM plugins are extensions that, when enabled, are called automatically by the model during user interactions. They operate under the model’s control, and the application lacks influence over their execution. Due to constraints related to context size, plugins may adopt free-text inputs from the model without implementing validation or type checking. This opens the door for a potential attacker to craft a malicious request to the plugin, leading to various undesirable outcomes, including potential remote code execution. For instance, a plugin can accept raw SQL or programming statements instead of parameters.Excessive Agency
The underlying reason behind this vulnerability usually is one of the following: excessive functionality, or permissions or autonomy of the model’s ability to undertake actions in response to a prompt. For example, a plugin to read the current user’s document store connects to the document repository with a privileged account that has access to all users’ files (excessive permissions).Overreliance
Although LLMs have the capability to generate content that is both creative and informative, there is a flip side where they may produce content that is factually inaccurate, inappropriate, or unsafe. This phenomenon is commonly known as hallucination or confabulation. As an example, LLMs may propose code that is insecure or flawed, potentially introducing vulnerabilities when integrated into a software without adequate supervision or verification.Model Theft
Organizations and researchers should give precedence to implementing strong security measures to safeguard their LLM models. This involves ensuring the confidentiality and integrity of their intellectual property, as well as preventing unauthorized access and the exfiltration of LLM models. Example: an attacker queries the model API using crafted inputs and prompt injection techniques to collect a sufficient number of outputs to create a shadow model.AI Threats and Considerations
In addition to the vulnerabilities mentioned by the OWASP document, there are other factors that must be taken into account when implementing AI systems. First, it should be noted that training sets govern the model’s behavior, so any modification to them would alter the system. Therefore, it is advisable not to base the model’s training on entirely public data from the internet. Similarly, it’s important to consider the noise added to the training set data, as adding too much noise to an image, for instance, could alter the weights or coefficients in the neural network, increasing the likelihood of failure. However, not adding noise would make it easier for malicious attackers to extract information using attacks such as model inversion. To prevent this type of reconstruction attack, it is crucial never to reveal the weights and not provide confidence levels to regular users in any way. This is done to avoid the risk of a membership inference attack. In the same way, the model should be able to explain where it gets the data, how it collects and transforms it without revealing important information about itself. Similarly, it should be fair and not exhibit discriminatory biases, as favoring certain groups of people can be seen as manipulation and may influence certain processes. Therefore, depending on its use, it can be dangerous. In addition to this, deprecated or redundant data increases the risk of overfitting, where the model becomes overly specialized to the training data and performs poorly on new, unseen data. Duplicate or highly correlated data in the training dataset leads to potential issues during model training and inference phases.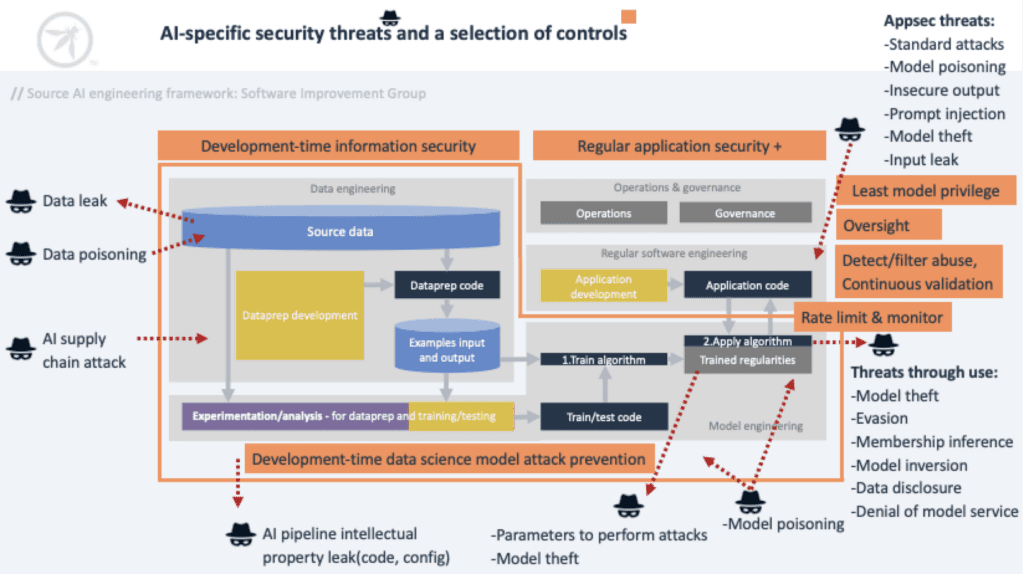
Proactive Security Measures
In the quest for robust AI defenses, exercising stringent oversight on LLM integration within backend systems is paramount. This entails equipping LLMs with specific API tokens that align with their roles, ensuring that they are equipped only with permissions essential for their functions — true to the principle of least privilege. By segregating and labeling external content, we can curtail its potential influence on user prompts, such as utilizing ChatML in OpenAI API calls to clearly communicate the origin of input data to the LLM. A zero-trust model should be the norm, treating LLM interactions with the same skepticism as any external entity, demanding comprehensive validation of the model’s outputs before they’re processed further.
Consider the caution needed when designing plugins, like one for summarizing emails; such tools must be restricted to their core purpose, avoiding the assumption of potentially harmful capabilities. It’s also wise to deconstruct complex operations into simpler components, delegating them to specialized agents, thus mitigating risks and reducing the chance of erroneous outputs. Centralizing the management of ML models through a registry fortifies the system against illicit access, buttressed by stringent access controls, authentication checks, and diligent activity monitoring.
Embracing such measures fortifies the security posture of LLM applications, shielding them from a spectrum of vulnerabilities. For a deeper understanding of preemptive strategies, the official OWASP guidelines for LLM offer a trove of resources to fortify your AI applications against the diverse threats of the digital age.